Ganze Internetprojekte herunterladen mit wget – robots.txt ignorieren
Ich wäre fast verzweifelt. Mit wget kann man bekanntlich ganze Internetprojekte rekursiv herunterladen. Mit einem einfachen wget -r -l2 [URL] kann man ein ganzes Projekt inklusive links bis zur zweiten Ebene herunterladen. Dies mache ich öfter wenn zB ein Tutorial auch offline verfügbar sein soll oder ich die Gefahr wittere das es eines tages einfach verschwinden könnte.
Nun hatte ich einmal so ein Tutorial [1] das sich nicht herunterladen lies. Die Ursache war mir völlig unbekannt und man wget brachte mich auch nicht wirklich weiter bis ich in einer Dokumentation [2] auf -e robots=off stieß.
Ich schaute in die robots.txt auf der besagten Seite und stellte fest das dort folgendes eingetragen war:
User-agent: *
Disallow: /
Die robots.txt ist eigentlich an Suchmaschinen gerichtet um anzuweisen das eine Seite nicht indexiert wird. In diesem Fall ist das natürlich völliger Unfug den Anleitungen im Internet sind selbstverständlich zum gefunden und gelesen zu werden. Da wget aber die robots.txt beachtet fühlt er sich angesprochen und lädt die besagten Dateien nicht herunter.
Die obige Anweisung wird also erweitert: wget-e robots=off -r -l2 [URL] und wget wird die robots.txt ignorieren und wie gewünscht alles herrunterladen.
Nachtrag:
möchte man das wget dauerhaft die robot.txt ignoriert kann man diese Option auch in die Konfigurationsdatei von wget schreiben. diese befindet sich im im home (~/.wgetrc). Falls nicht muss sie noch erstellt werden.
Chrome und Firefox, Seite neuladen ohne den Cache zu verwenden
Wenn man gerade dabei ist Webseiten zu bearbeiten und Kleinigkeiten am Design durchführt, ist es manchmal lästig den Cache des Browsers auf null zu stellen. Macht man dies nicht, nützt ein Reload mit F5 recht wenig den dann läd der Browser einfach aus dem Cache.
Die meisten die mit so etwas zutun haben werden es sicherlich wissen aber es gibt da einen kleinen Banalen Trick: STRG+F5
Achtung, dieser Artikel ist an erfahrene Benutzer gerichtet. Nichtbefolgen oder eigenmächtiges Handeln kann zum Verlust des Systems und/ oder Daten führen!
Oft höre und lese ich die Frage „Soll ich als root oder lieber mit sudo administrationsarbeiten durchführen?“ Genauso oft höre ich „Bei Ubuntu habe ich gar kein root-Passwort!„. Ich möchte in diesem Beitrag ganz kurz auf diese beiden Fragen eingehen. Also, der Benutzer root wird grundsätzlich nur mit login-passwort benötigt wenn der eigentliche Systemverwalter gar keinen Benutzeraccount auf diesem Computer/ System hat oder benötigt. Dies trifft z.B auf einer Serverfarm zu, da wäre es Unsinn wenn der root sich extra einen Benutzer anlegen müsste um irgend welche Veränderungen vorzunehmen.
Ist der Computer eine Arbeitsstation, wie sie jeder zuhause hat, an der ganz normal gearbeitet wird und jemand im Haushalt auch die Administration übernimmt, ist der Benutzer root absolut unnötig. Dies bedeutet nicht das man ihn nicht benötigt, sondern das man für diesen kein Passwort benötigt. Wieso das so ist? Ganz einfach …
Diejenigen die sowieso einen Benutzeraccount auf diesem Rechner besitzen, können jederzeit (falls sie ein sudoers sind, dazu gleich mehr) mit sudo <KOMMANDO> einen Befehl mit root-rechten ausführen. Benötigt man wirklich einmal eine echte root-login shell hilft der Befehl sudo -i
Dieser startet ohne weitere Parameter eine root-login-shell! In der Datei /etc/sudoers befinden sich alle Benutzer die sudo einsetzen dürfen. Bearbeiten darf man diese Datei nur mit dem dafür speziel vorgesehenen Tool visudo, nur dann ist gewährleistet das die Datei syntaktisch einwandfrei ist. Hat man den neuen sudo-Zugang getestet und ist dieser einwanfrei kann man getrost in der Datei /etc/shadow das Passwort des Benutzers root herrauslöschen. Die Zeile könnte dann so aussehen:
root::17068:0:99999:7:::
Die Passwörter in dieser Datei sind übrigends verschlüsselt und das Passwort würde sich hinter dem ersten Doppelpunkt befinden. Will man ein Passwort wieder herstellen und den root-Zugang wieder zulassen hilft ein sudo passwd root … zack ist alles wieder beim alten.
So, das sollte ersteinmal gekärt sein, root ist also absolut unnötig. Ist root auf diese weise deaktiviert gibt es noch einen positiven Nebeneffekt: Für root benötigt man zwei Passwörter, einmal für den eigentlichen Benutzer und ein zweites mal für sudo -i. Vor alleim bei rootservern für die Wartung aus der Ferne ist es Gold wert.
Kleiner Tipp zum Schluss: Bei solchen Arbeiten am System, bei dem man sich bei einem kleinen Tippfehler selbst aussperren kann, IMMER eine zweite Konsole öffnen mit z.B STRG-ALT-F2! Bei Fernwartung entsprechend ein zweites mal per ssh einloggen im Hintergrund. DANN ERST LOSLEGEN!
Änderungslog des Beitrags:
03/02/2018 – erste Version des Beitrags
13/03/2018 – kleine unbedeutende Änderungen wie zB Rechtschreibung.
Dieser Artikel basiert in der ersten Version auf eigenen Gedanken und dieser Quelle[1]. Oft ist es notwendig bestimmte Angaben eines Programms dauerhaft zu speichern. Diese Angaben stellen die grundlegendsten Einstellungen dar wie z.B welche Datenbank soll beim Programmstart verwendet werden. Alle weiteren Einstellungen könnte man aus der Datenbank laden doch hier geht es um die absoluten Basisdaten.
Grundsätzlich ist es ja bei den ersten Gedanken überhaupt kein Problem solche Angaben zu speichern, da gibt es viele Möglichkeiten. Zum einen einfach in eine Testdatei schreiben oder die alte Properties aus java.util.Properties[2]. Problematisch wird das ganze erst wenn wir uns Plattform-übergreifend bewegen. Hier beschäftigen wir uns aber erst einmal rein mit der java.util.prefs.Preferences[3] Klasse.
Die Preferences Klasse geht bei dem ganzen noch einen Schritt weiter, wir müssen uns als Entwickler gar nicht mehr darum kümmern wo diese Daten gespeichert werden, das erledigt für uns das jeweilige Betriebssystem. Unter Linux liegt es im ~/.java/ Verzeichnis und unter Windows je nach Version im Dokumenten-Ordner, Appdata oder auch der Registry. Dazu später mehr.
Von der o.g Quelle hole ich mal den dort vorliegenden Quelltext, übersetze die Kommentare und arbeite das ganze etwas auf. Zum Schluss gibt es das ganze fertig zum Download und zum ausprobieren. Jetzt eber erst einmal den original Quelltext:
import java.util.prefs.Preferences;
public class PreferenceTest {
private Preferences prefs;
public void setPreference()
{
prefs = Preferences.userRoot().node("/data");
String ID1 = "Test1";
String ID2 = "Test2";
String ID3 = "Test3";
System.out.println(prefs.getBoolean(ID1, true));
System.out.println(prefs.get(ID2, "Hello World"));
System.out.println(prefs.getInt(ID3, 50));
prefs.putBoolean(ID1, false);
prefs.put(ID2, "Hello Europa");
prefs.putInt(ID3, 45);
prefs.remove(ID1);
}
public static void main(String[] args)
{
PreferenceTest test = new PreferenceTest();
test.setPreference();
}
}
Was passiert hier nun also?
Ich habe bewusst die Kommentare aus dem Code herausgelassen und hole es hier nun nach. Also:
Zeile 10:
Definieren wir einen „node“, wo die Daten gespeichert werden können. Es gibt da mehrere Möglichkeiten. Hier einfach nur als String in Form eines Pfades. Schau Dir die Klasse im javadoc [3] genauer an, es gibt noch andere Möglichkeiten die nodes zu definieren.
Der überwiegende Teil bezieht sich auf die Nutzerrechte. Globale und lokale Konfiguration als Stichwort.
Zeile 15-17:
Wir laden Werte testweise aus einer eventuell vorhandenen Konfiguration mit der Methode .get diese läd die Daten in eine Variable. Hinter dem Kommata können default-Werte eingetragen werden falls es die Daten oder den ganzen node nicht gibt.
Zeile 19-21:
Hier speichern wir die aktuellen Werte aus den Variablen in unsere Konfiguration.
Zeile 23:
Hier löschen wir testweise einen Wert aus dem node.
Wo werden die Daten gespeichert?
Genau das ist nun der Trick an der ganzen Sache. Wir müssen uns eben nicht darum kümmern WO diese Daten gespeichert werden. Überlassen wir das dem Betriebssystem wo der Container ausgeführt wird. Wie dies allerdings unter Windows und Ubuntu aussieht zeige ich eben an zwei Screenshots.
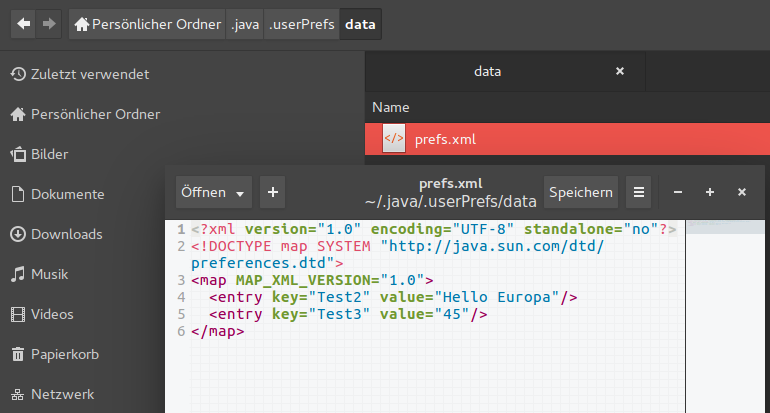
Bild 1 – Linux
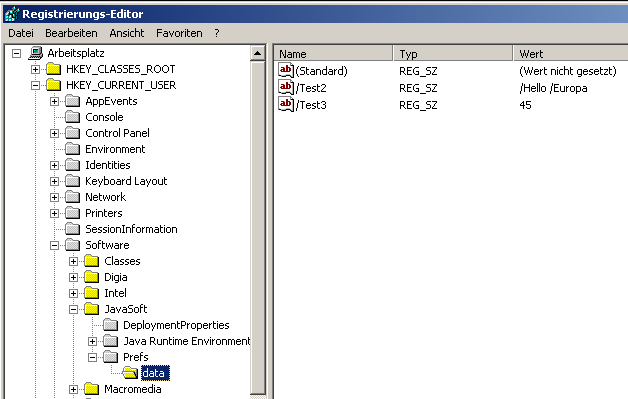
Bild 2 – WindowsXP
Ja genau, ein und der gleiche Code aber unter Linux wird dies unter ~/home/.java/.userPrefs/data/prefs.xml gespeichert und unter Windows in der Registry im Zweig HKEY_CURRENT_USER -> Software -> JavaSoft -> Prefs -> data
Wo dies genau gespeichert wird legen in Zeile 9 fest. Es lässt sich auch definieren das dies im System Zweig der Registry oder /etc/.java unter Linux gespeichert wird. Dazu muss der Container allerdings als Administrator oder root gestartet werden. Ich nehme an es ist verständlich worum es geht.
Eine komplette Liste, wo auf welchem System die nodes gespeichert werden, liefere ich nach aber dies sollte für Dich als Entwickler allerdings zweitrangig sein.
— Fortsetzung folgt …
Achja, ein Tipp am rande. Viele Anfänger tendieren dazu darauf zu bestehen das ihre Daten relativ zum Container gespeichert werden. Am besten in einem Unterverzeichnis unterhalb des Containers. Geht bitte davon ab, das ist nicht wirklich sinnvoll. Stellt euch vor jemand möchte euer Programm an einer globalen Stelle für alle Benutzer installieren. An dieser Stelle hätte der Benutzer der das Programm ausführt gar keine Schreibrechte. Für diesen Einsatz wäre also euer Programm unbrauchbar. Falls es wirklich unbedingt nötig sein sollte, musst Du Dir die Klasse java.util.Properties [2] anschauen die allerdings schon ein paar Jahre auf dem Buckel hat. Dazu gibt es bald noch einen eigenen Beitrag.
Du hast Fragen zur java.util.prefs.Preferences Klasse, Anmerkungen oder bist völlig anderer Meinung? Teile es bitte hier im Forum mit.
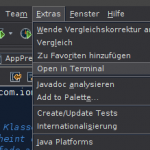
Netbeans besitzt eine eigene Konsole die man schnell aufrufen kann. Unter Dateien (Bild 1) wählt man einen Pfad und anschließend unter „Extras“ -> „Open in Terminal„.
Bild 1
Bild 2
Ich verwende hier in diesem Beispiel die deutschsprachige Version direkt von Oracle. In der Englischen Version kann der Weg lauten: „IDE Tools“ -> „Terminal„. Den sich öffnenden Reiter kann man anschließend überall hinziehen, wo man ihn gerade braucht. Sinnvoll wäre es im unteren Bereich, wo auch die Ausgabe erfolgt bei einem RUN, oder auch im Editor-Bereich.
Du hast Fragen zu Netbeans? Gerne beantworte ich oder andere diese im IDE-FORUM
Cookie-Zustimmung verwalten
Um dir ein optimales Erlebnis zu bieten, verwenden wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.