Wie lagere ich ein Fenster aus der Oberfläche aus, um es z.B. auf einen separaten Monitor zu ziehen?
Fenster, die nicht in die Arbeitsoberfläche eingebettet, sondern
darüber schweben sollen, um sie beispielsweise auf einen Zweit-
monitor auszulagern, fasst Du am Anfasser und hällst beim Zie-
hen die (SHIFT)-Taste gedrückt. Ein kurzes Ziehen reicht, und Du erhällst ein Duplikat des Editors in einem neuen schwebenden Fenster.
Mit dem Windows Explorer auf eine SSH Quelle wie auf ein Netzlaufwerk zugreifen
2024-04-18 06:24:56 Thursday
Guide/ Tutorial – Anleitung – Windows 10/ 11
Problem:
Kurzversion
Wie verbindet man sich mit dem Windows-Explorer über SSH mit einem Linux-Server so das Dateien übertragen werden können?
Hintergrund
Es ist durchaus angenehm, gelegentlich eine SSH Verbindung zu einem Server mit dem Windows Explorer, um den SSH-Server als Netzlaufwerk verfügbar zu haben. Persönlich nutze ich diese Methode, indem ich mich zunächst über VPN mit dem entsprechenden Server verbinde und dann den Linux-Account per SSH in Windows einbinde. Auf diese Weise steht mir das Verzeichnis /home/benutzer/, als Linux-Netzlaufwerk zur Verfügung. Natürlich ist dies auch ohne VPN möglich, jedoch sollte man auf entfernten Servern so wenig Dienste wie möglich öffentlich zugänglich machen. Auf meinen eigenen Servern leite ich beispielsweise nur Port 1029 UDP weiter, obwohl verschiedene Dienste aktiv sind die erreichbar sein sollen.
Theoretisch könnte jemand beispielsweise einen Raspberry Pi lokal betreiben und Daten ohne zusätzliche Dienste wie FTP oder ähnliches übertragen wollen. Oft wird dafür Samba (SMB bzw. CIFS) verwendet, um eine sogenannte „Windows-Freigabe“ einzurichten. Allerdings stellen diese zusätzlichen Dienste potenzielle Sicherheitsrisiken dar. Spätestens zu diesem Zeitpunkt sollte man sich Gedanken über die Sicherheit machen. Daher erledige ich diese Aufgaben gerne schnell und sicher per SSH, da diese Methode ohnehin fast immer verfügbar ist.
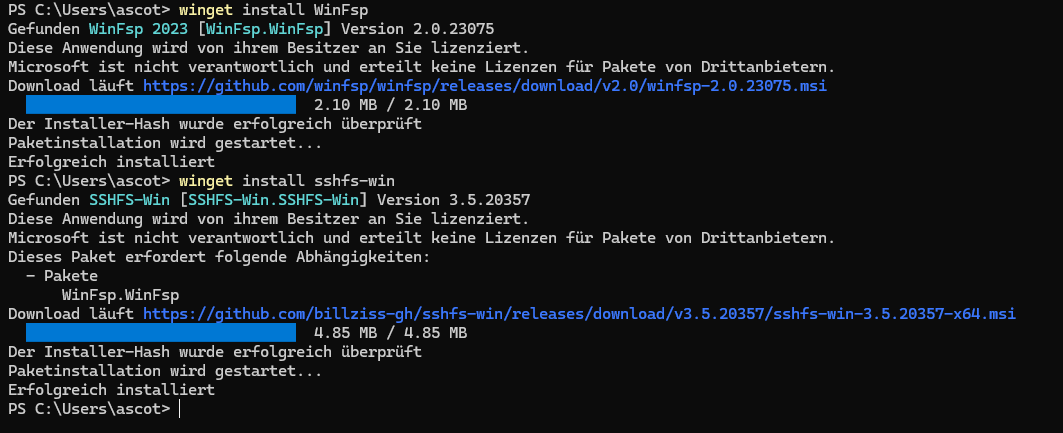
Diese Anwendungen lassen sich in dieser Reihenfolge entweder direkt von GitHub installieren oder, wie ich es bevorzuge, per winget in der Windows PowerShell installieren.
Bei winget handelt es sich um ein etwas weniger bekanntes Tool das im entferntesten Sinne mit apt unter Linux vergleichbar wäre. [LINK]
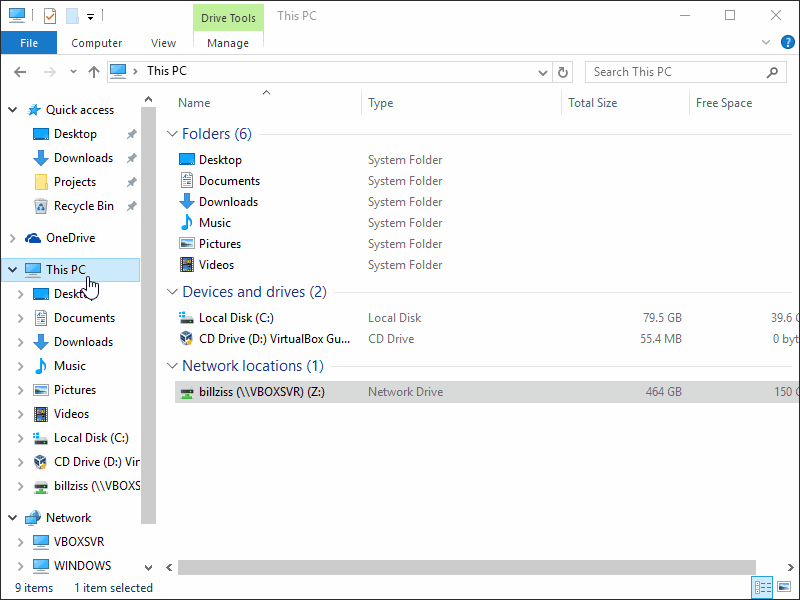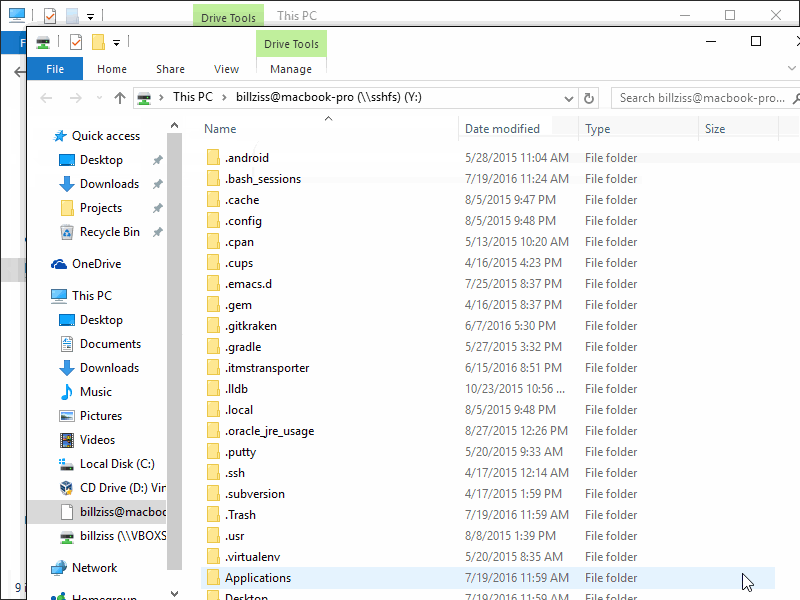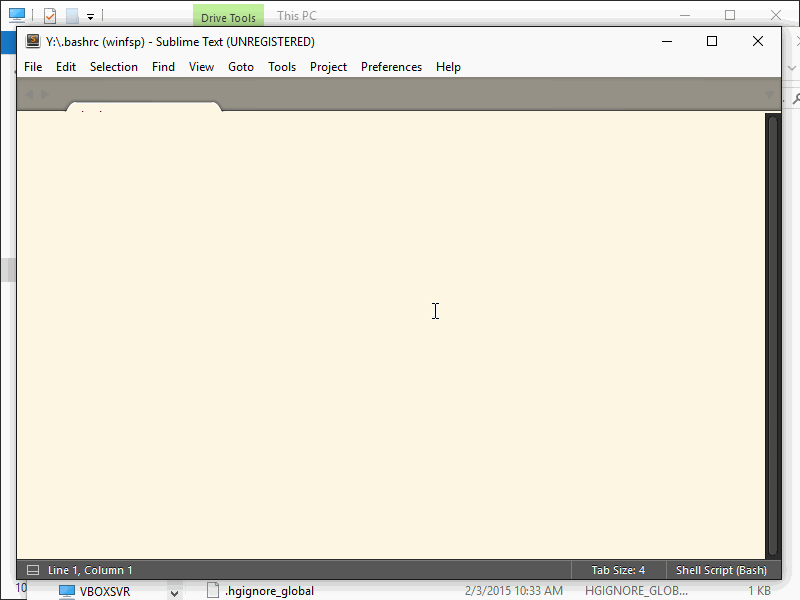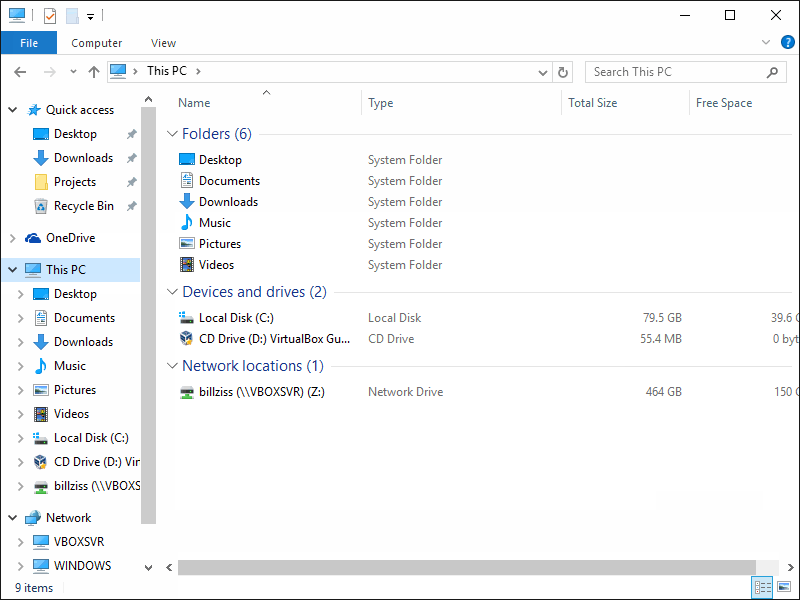
Verbindung:
Verbunden wird nun genauso wie jedes andere Netzlaufwerk mit der Ausnahme das der Verbindung ein \sshfs\ vorrangestellt wird.
Das klingt nach einer äußerst vielseitigen Vorgehensweise! Durch die Installation und Konfiguration über GitHub und die Verwendung von SSH können die Zugriffsmöglichkeiten auf dem Linux-Server entsprechend der üblichen Benutzerverwaltung eingestellt werden. Dies ermöglicht die individuelle Vergabe von Lese- und Schreibrechten für jeden SSH-Account. Es lohnt sich definitiv, die Anleitungen der jeweiligen Pakete auf GitHub zu lesen, um weiterführende Informationen zu erhalten und das volle Potenzial dieser Methode auszuschöpfen.
Zu beachten bei der Verbindung sei eine Besonderheit. Läuft auf dem Server SSH eingehend, nicht auf dem Standart-Port 22, dann ist das Ausrufezeichen (!) statt des üblichen Doppelpunkts zu verwenden.
Manchmal kann es vorkommen, dass Code aus dem Google-Authenticator plötzlich nicht mehr angenommen werden. Es erscheint nach jeder Eingabe stets die Meldung, dass der Code nicht gültig sein. Mir persönlich ist das mal passiert als ich mich in Plesk meines Servers einloggen wollte.
Jetzt nur nicht in Panik geraten! Neben der Möglichkeit herauszufinden, wie man den Authenticator in dem entsprechenden Dienst deaktiviert, gibt es eventuell eine viel banalere Lösung.
Eine der möglichen Fehler dabei ist, dass die Zeiten zwischen dem Mobilgerät auf dem der Authenticator läuft, dem Google Server und dem eigenen Dienst, bei dem man sich einloggen möchte, nicht synchron sind.
Zur Lösung geht man wie folgt vor.
App Google Authenticator starten/ öffnen
Oben rechts in der Ecke gibt es drei Punkte. Diese berühren und dann im Menü „Einstellungen“ wählen.
Anschließend die Option „Zeitkorrektur für Codes“ auswählen.
nun „jetzt synchronisieren„.
Mit etwas Glück ist der Spuk vorbei und man kann sich wie gewohnt einloggen. Bei Anregungen und Tipps, gerne über das Kontaktformular eine Info an mich.
Markdown und HTML Sprungmarken bzw. Querverweise innerhalb eines Dokuments
Links innerhalb HTML und Markdown Dokumenten
Kurz in eigenes Sache, ich schreibe so gut wie alle meine Texte in reinen Markdown. Wandel diese bei Bedarf selbst in HTML um oder verarbeite es mit zB. Pandoc weiter. Bei langen Artikeln oder einem E-Book stellt man sich dann die Frage, wie erstelle ich eine Sprungmarke innerhalb des Dokuments. Sagen wir mal vom Inhaltsverzeichnis zur richtigen Stelle? Inhaltsverzeichnis mit Markdown erstellen ist sowieso so eine Sache.
Eins vorweg, Markdown stellt dazu nur indirekt ein Werkzeug zur Verfügung. Allerdings lässt sich HTML und Markdown sehr gut mischen, daher machen wir einen kleinen Umweg.
Zuerst erstellen wir einen Link und verweisen auf einen Anker in Markdown:
<a href="#kapitel1">Kapitel 1</a>
Der Teil in den eckigen Klammern ist das, was man später sehen kann, in den runden Klammern befindet sich der Name des Ankers zu dem gesprungen werden soll. Das ganze sieht dann wie folgt aus:
Nun erstellen wir die Stelle an die gesprungen werden soll:
<a id="kapitel1"></a>
## Kapitel 1
oder:
<a name="kapitel1"></a>
## Kapitel 1
Dies sieht dann im Browser wie folgt aus:
Kapitel 1
Mit Klick auf den Link Kapitel 1 oben, springt man sofort zur Marke des <a> Tags. Ich persönlich bevorzuge die Sprungmarke immer ein kleines Stück über die eigentliche Stelle zu platzieren, da die meisten Browser fast schon zu weit springen.
Auch nehme ich am liebsten den Namen des <a> Tags als Sprungmarke, theoretisch wäre auch jede beliebige ID eines anderen Tags möglich wie z. B. <div id="kapitel1">. Da ich mich jetzt aber auf Markdown beziehe bleiben wir beim Ersten. Des Weiteren könnte man auch in Namenskonflikte mit Javascript geraten. Sollte aus dem Markdown-Code eh nur PDF Dateien generiert werden, spielt dies eh keine Rolle.
Änderungslog:
2024-04-22 09:32:55 Monday<a name= gegen <a id= getauscht/ ergänzt
Den USB Stick oder Festplatte an einer Fritzbox unter Linux mounten
Bearbeitet: 2024-11-02 10:25:07 Saturday
Der Tipp bezieht sich nicht auf eine ganz bestimmte Linux-Distribution obwohlich hier nur Manjaro erwähne.
Hier nur ganz kurz auf die Schnelle. Nach Neuinstallation eines Manjaro-Linux Systems konnte die Windowsfreigabe einer Fritzbox nicht mehr gemountet werden über die /etc/fstab. Zuerst habe ich schnell CIFS installiert mit sudo pacman -S cifs-utils.
Obwohl es die gleiche fstab aus einem Backup war, kam beim Versuch zu mounten folgende Fehlermeldung:
[work /]# mount -a
mount error(112): Host is down
Refer to the mount.cifs(8) manual page (e.g. man mount.cifs)
Der ensprechende Eintrag in der /etc/stab sah wie folgt aus:
Das Passwort habe ich unter /root/.smbcredentials gespeichert, damit man es beim booten nicht eingeben muss. Die Fehlermeldung blieb und der Server war selbst verständlich nicht erreichbar.
Was war passiert? Ein Blick in man mount.cifs, wie die Fehlermeldung geraten hatte brauchte folgendes zum Vorschein (Auszug):
vers=arg
SMB protocol version. Allowed values are:
· 1.0 - The classic CIFS/SMBv1 protocol.
· 2.0 - The SMBv2.002 protocol. This was initially introduced in Windows Vista Service Pack 1, and Windows Server 2008. Note that the initial release version of Windows Vista spoke a slightly
different dialect (2.000) that is not supported.
· 2.1 - The SMBv2.1 protocol that was introduced in Microsoft Windows 7 and Windows Server 2008R2.
· 3.0 - The SMBv3.0 protocol that was introduced in Microsoft Windows 8 and Windows Server 2012.
· 3.1.1 or 3.11 - The SMBv3.1.1 protocol that was introduced in Microsoft Windows Server 2016
Also habe ich die /etc/fstab schnell angepasst in:
Eigentlich wollte ich einen kurzen knappen Beitrag darüber schreiben, wie man Software am besten versioniert. Nach kurzer Überlegung fiel mir aber sehr schnell SemVer ein, ein Verfahren, das sich eigentlich perfekt durchgesetzt hat, aber noch nicht einmal im deutschsprachigen Wikipedia-Artikel Einklang findet außer einen Link.
! Package babel Error: You haven't specified a language option.
Was wenn Lyx manchmal, gerade nach einer Neuinstallation obige Fehlermeldung ausspuckt wenn man eine Datei im PDF-Format betrachten möchte? Bei mir hilft immer folgendes:
Ganze Internetprojekte herunterladen mit wget – robots.txt ignorieren
Ich wäre fast verzweifelt. Mit wget kann man bekanntlich ganze Internetprojekte rekursiv herunterladen. Mit einem einfachen wget -r -l2 [URL] kann man ein ganzes Projekt inklusive links bis zur zweiten Ebene herunterladen. Dies mache ich öfter wenn zB ein Tutorial auch offline verfügbar sein soll oder ich die Gefahr wittere das es eines tages einfach verschwinden könnte.
Nun hatte ich einmal so ein Tutorial [1] das sich nicht herunterladen lies. Die Ursache war mir völlig unbekannt und man wget brachte mich auch nicht wirklich weiter bis ich in einer Dokumentation [2] auf -e robots=off stieß.
Ich schaute in die robots.txt auf der besagten Seite und stellte fest das dort folgendes eingetragen war:
User-agent: *
Disallow: /
Die robots.txt ist eigentlich an Suchmaschinen gerichtet um anzuweisen das eine Seite nicht indexiert wird. In diesem Fall ist das natürlich völliger Unfug den Anleitungen im Internet sind selbstverständlich zum gefunden und gelesen zu werden. Da wget aber die robots.txt beachtet fühlt er sich angesprochen und lädt die besagten Dateien nicht herunter.
Die obige Anweisung wird also erweitert: wget-e robots=off -r -l2 [URL] und wget wird die robots.txt ignorieren und wie gewünscht alles herrunterladen.
Nachtrag:
möchte man das wget dauerhaft die robot.txt ignoriert kann man diese Option auch in die Konfigurationsdatei von wget schreiben. diese befindet sich im im home (~/.wgetrc). Falls nicht muss sie noch erstellt werden.
Um dir ein optimales Erlebnis zu bieten, verwenden wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.